A Recommander System Architecture Design
As the second installment in a blog series on Machine Learning system design, I present a straightforward architecture for training and maintaining a recommender system tailored to video sharing platforms such as YouTube.
This problem of ML system design consists of two major building blocks:
1- Offline component: This component focuses on training and validating the recommender model.
2- Online component: This component is responsible for generating (inferring) recommendations in real-time.
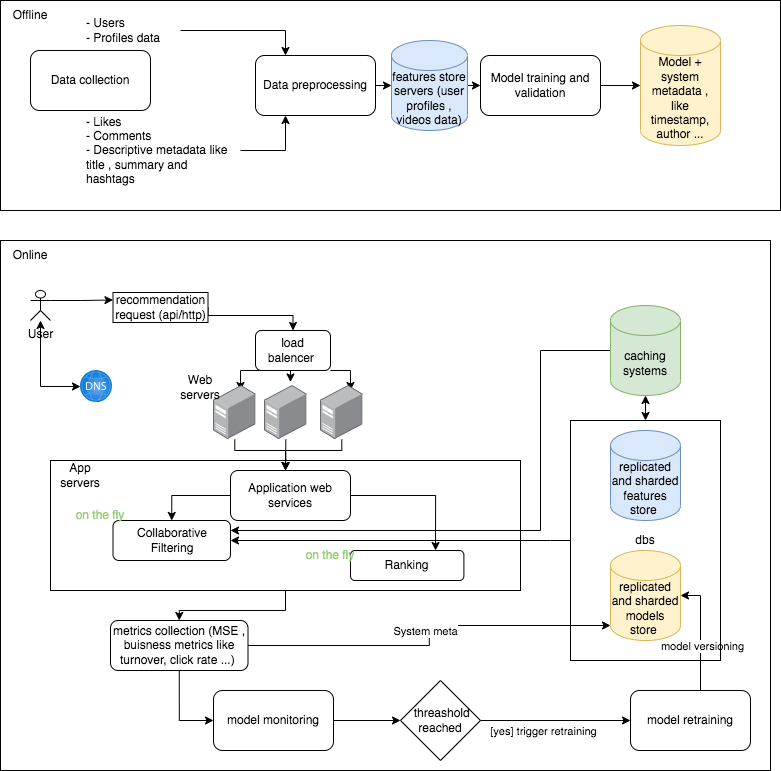
The initial offline training process follows the classic Data Science lifecycle, beginning with data collection and transformation into features, and concluding with model building and validation. The outcome of these steps is a dataset that captures the features and is stored in a feature store, along with a model that is persisted in a blob storage medium, such as a distributed file system like S3.
This article focuses specifically on the online component. In this subsystem, a user submits a request through a REST API, for instance. The request is then forwarded to an application server that encompasses the recommender functions. In our architecture, we propose utilizing a load balancer to provide increased scalability, performance, reliability, and redundancy to the service layer []. Scaling this layer horizontally enables us to handle requests from billions of users and deliver improved response times by minimizing throughput.
As depicted in the architecture, the recommender module consists of two components: (i) a content filtering (CF) algorithm that identifies relevant videos for each user based on their profile and historical viewing data, and (ii) a ranking algorithm that assigns scores to the recommended videos.
The techniques employed in content filtering (CF) can range from basic approaches, such as simple similarity matching, to more advanced methods involving deep neural network models. In this particular example, we focus on utilizing a model as hinted in the above paragraphs. At inference, the CF algorithm reads the model from the model store and other relevant features (e.g. user profile data) from the features store and predicts the best movies that match the user and it’s viewing history. In this architecture, we utilize an in-memory caching system to reduce data retrieval latencies that may arise when accessing a slower storage layer.
After generating the recommendation, the algorithm sends business metrics like turnover and click rates, and system-level metadata like the inference timestamp and its response time to the model store. These metrics help in (i) assisting the decision-making process behind triggering the model retraining and (ii) feeding the monitoring dashboard. Triggering the retraining of the model can occur in a timely manner (for instance, daily model retraining). It can also result from reaching a certain threshold due to data drift and concept drift events.